My book

My book, Designing Data-Intensive Applications, has received thousands of five-star reviews.
Published by Martin Kleppmann on 25 Nov 2014.
tl;dr: I have created a test suite for comparing the transaction isolation levels in different databases. I did this as background research for my book. This post explains why.
First came the NoSQL movement, with its siren call that our systems could be so scalable, so much faster and so highly available if we just abandon ACID transactions and make our systems BASE instead.
Then came the concurrency bugs — for example, the Bitcoin exchange that was almost bankrupted because it had a race condition on outgoing payments. (An attacker circumvented the account balance check by making many concurrent transactions, and thus was able withdraw more money than they had in their account. And this wasn’t even the only case.)
Internet commenters, in their infinite wisdom, were quick to point out that if you’re dealing with money, you had better use an ACID database. But there was a major flaw in their argument. Most so-called ACID databases — for example Postgres, MySQL, Oracle or MS SQL Server — would not have prevented this race condition in their default configuration.
Yes, you read that right. Those databases — the ones that have probably processed the vast majority of commercial transactions over the last 20 years — do not by default guarantee that your transactions are protected from race conditions. Let me explain.
Among the ACID properties, the letter I stands for isolation. The idea of isolation is that we want our database to be able to process several transactions at the same time (otherwise it would be terribly slow), but we don’t want to have to worry about concurrency (because it’s terribly complicated). In an ideal world, the database could guarantee that transactions behave as if they executed without any concurrency, one after another, serially — in other words, they are serializable.
Unfortunately, most implementations of serializability have quite bad performance. The team working on the first SQL database (System R) already realised this in 1975, and decided to offer weaker isolation levels than serializability. Those isolation levels would not quite prevent all race conditions, but they had much better performance, so it was considered an acceptable trade-off. That research group made up some names for those weak isolation levels (“repeatable read”, “read committed”, and “read uncommitted”). 39 years later, some implementation details have changed, but on the whole isolation levels still look remarkably similar to System R.
The problem, however, is this: in order to understand what those isolation levels mean, you pretty much have to understand how the database implements concurrency control internally. The levels basically have no intuitive meaning, because they are an incredibly leaky abstraction — they are defined by implementation detail, not because someone thought they’d make a great API. And that’s also why they are so hard to understand.
Here’s a challenge for you: can you find any colleague in your organisation who can explain — off the cuff and without looking at the docs — the difference between “repeatable read” and “read committed”, including an example situation in which they behave differently? And what about the difference between “repeatable read”, “snapshot isolation” and “serializable”?
If you can find such a person, I bet they worked on database systems previously. I can’t imagine there are many application developers who really understand isolation levels, because they are so confusing. Application developers are smart, but they have more important things to worry about than obscure implementation details of databases.
That’s a big problem. The isolation level is part of the database’s API. It’s just as important as the data model. People have endless debates about relational vs. document vs. other data models, but I’ve never overheard a heated debate about isolation levels — only seen slightly embarrassed smirks signifying “I really ought to know more about this, but I don’t”.
If you don’t understand the concurrency guarantees, you have no idea whether your code will still behave correctly when processing a few simultaneous requests. You can’t easily write unit tests for concurrency, either. How do you know your code is correct?
Fortunately, some academic researchers have been on the case, creating formal models of isolation levels and proving some of their properties. For example, Peter Bailis et al. at Berkeley have been doing some good work in this area. It’s not yet easy to understand, but at least it’s logically sound.
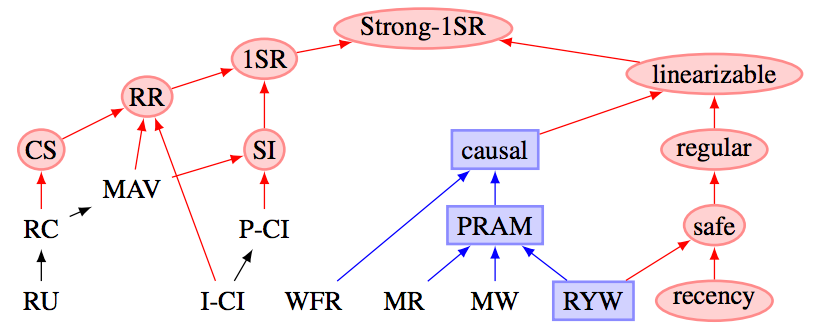
You may have seen this diagram from their VLDB paper, which shows the relative strength of different isolation levels, and also relates them to availability (as per the CAP theorem). It has also appeared in Kyle Kingsbury’s “Linearizable Boogaloo” talk (around 8:30). In this diagram, 1SR = serializability, RR = repeatable read, SI = snapshot isolation, RC = read committed.
Unfortunately, even though terms like repeatable read sound like they should be standardised (and indeed they are defined in the ANSI SQL standard), in practice different databases interpret them differently. One database’s repeatable read guarantees things that another doesn’t. Not only are the names of the isolation levels confusing, they are also inconsistent.
If you read the documentation of a database, the description of the isolation levels tends to be quite vague. How do you know what guarantees your application actually needs, and thus which isolation level you should use? How do you learn to look at a piece of code and say “this won’t be safe to run at read committed, it’ll need at least repeatable read”? Even better, could we write automated tests or type checkers which fail if we write code that is not concurrency-safe?
If we want any hope of reasoning about concurrency safety, we first need to understand exactly which guarantees existing databases do and don’t provide. We need to express those guarantees in terms of precisely defined, testable properties (not vague English sentences in the documentation). Research on isolation has produced those precise definitions, but as far as I know they so far haven’t been systematically tested on actual database implementations.
Hermitage is a small project that I started to address this. It is a test suite for databases which probes for a variety of concurrency issues, and thus allows a fair and accurate comparison of isolation levels. Each test case simulates a particular kind of race condition that can happen when two or more transactions concurrently access the same data. Each test can pass (if the database’s implementation of isolation prevents the race condition from occurring) or fail (if the race condition does occur).
The tests are fairly direct translations of the anomalies described in research papers. The properties that they check have quite obscure names (such as Predicate-Many-Preceders) and abbreviations (such as P4), but rather than inventing even more terminology I thought I’d rather stick with the terms in the literature.
So far I have ported and run this test suite on four relational databases: PostgreSQL, MySQL, Oracle DB and Microsoft SQL Server. But it’s not limited to old-school relational databases: in fact, it would be very interesting to run it with some of the recent “NewSQL” databases that claim to support ACID transactions. The whole point of this test suite is that it allows an exact comparison not just between isolation levels within one database, but across different databases.
For the details please check out the repository. To mention just a few highlights:
In the book I’m writing (Designing Data-Intensive Applications) I’m determined to explain transaction isolation in a way that we can all understand. But in order to write that chapter, I first had to understand isolation levels myself.
So Hermitage was primarily background research for the book, allowing me to write an easy-to-understand but accurate description of what databases do in practice. If you find Hermitage incredibly confusing, don’t worry: the book doesn’t go into all the detail of G1b, PMP, P4 and G2-item. I first had to make it complicated for myself so that I could make it simple (but accurate) for readers.
However, going beyond this book, I’m hoping that this little project can encourage others to explore how application developers interact with isolation. Simply cataloguing what databases actually do, using test cases rather than vague langauge, is a step forward.
And perhaps some enterprising researcher could take this further. For example, perhaps it’s possible to create a type system for transactions, which would allow static analysis of an application to verify that it doesn’t contain concurrency bugs when run at a particular isolation level. I don’t know enough about type systems to know whether that’s even possible – but if yes, it could potentially cut out a whole class of bugs that are very hard to find through testing.
Thank you to Peter Bailis and his collaborators for feedback on a draft of this post.
If you found this post useful, please support me on Patreon so that I can write more like it!
To get notified when I write something new, follow me on Bluesky or Mastodon, or enter your email address:
I won't give your address to anyone else, won't send you any spam, and you can unsubscribe at any time.
My book, Designing Data-Intensive Applications, has received thousands of five-star reviews.
![]() Unless otherwise specified, all content on this site is licensed under a
Creative Commons
Attribution 3.0 Unported License.
Theme borrowed from
Carrington,
ported to Jekyll by Martin Kleppmann.
Unless otherwise specified, all content on this site is licensed under a
Creative Commons
Attribution 3.0 Unported License.
Theme borrowed from
Carrington,
ported to Jekyll by Martin Kleppmann.