My book

My book, Designing Data-Intensive Applications, has received thousands of five-star reviews.
Published by Martin Kleppmann on 05 Dec 2012.
So you have some data that you want to store in a file or send over the network. You may find yourself going through several phases of evolution:
Once you get to the fourth stage, your options are typically Thrift, Protocol Buffers or Avro. All three provide efficient, cross-language serialization of data using a schema, and code generation for the Java folks.
Plenty of comparisons have been written about them already (1, 2, 3, 4). However, many posts overlook a detail that seems mundane at first, but is actually crucial: What happens if the schema changes?
In real life, data is always in flux. The moment you think you have finalised a schema, someone will come up with a use case that wasn’t anticipated, and wants to “just quickly add a field”. Fortunately Thrift, Protobuf and Avro all support schema evolution: you can change the schema, you can have producers and consumers with different versions of the schema at the same time, and it all continues to work. That is an extremely valuable feature when you’re dealing with a big production system, because it allows you to update different components of the system independently, at different times, without worrying about compatibility.
Which brings us to the topic of today’s post. I would like to explore how Protocol Buffers, Avro and Thrift actually encode data into bytes — and this will also help explain how each of them deals with schema changes. The design choices made by each of the frameworks are interesting, and by comparing them I think you can become a better engineer (by a little bit).
The example I will use is a little object describing a person. In JSON I would write it like this:
{
"userName": "Martin",
"favouriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}This JSON encoding can be our baseline. If I remove all the whitespace it consumes 82 bytes.
The Protocol Buffers schema for the person object might look something like this:
message Person {
required string user_name = 1;
optional int64 favourite_number = 2;
repeated string interests = 3;
}
When we encode the data above using this schema, it uses 33 bytes, as follows:
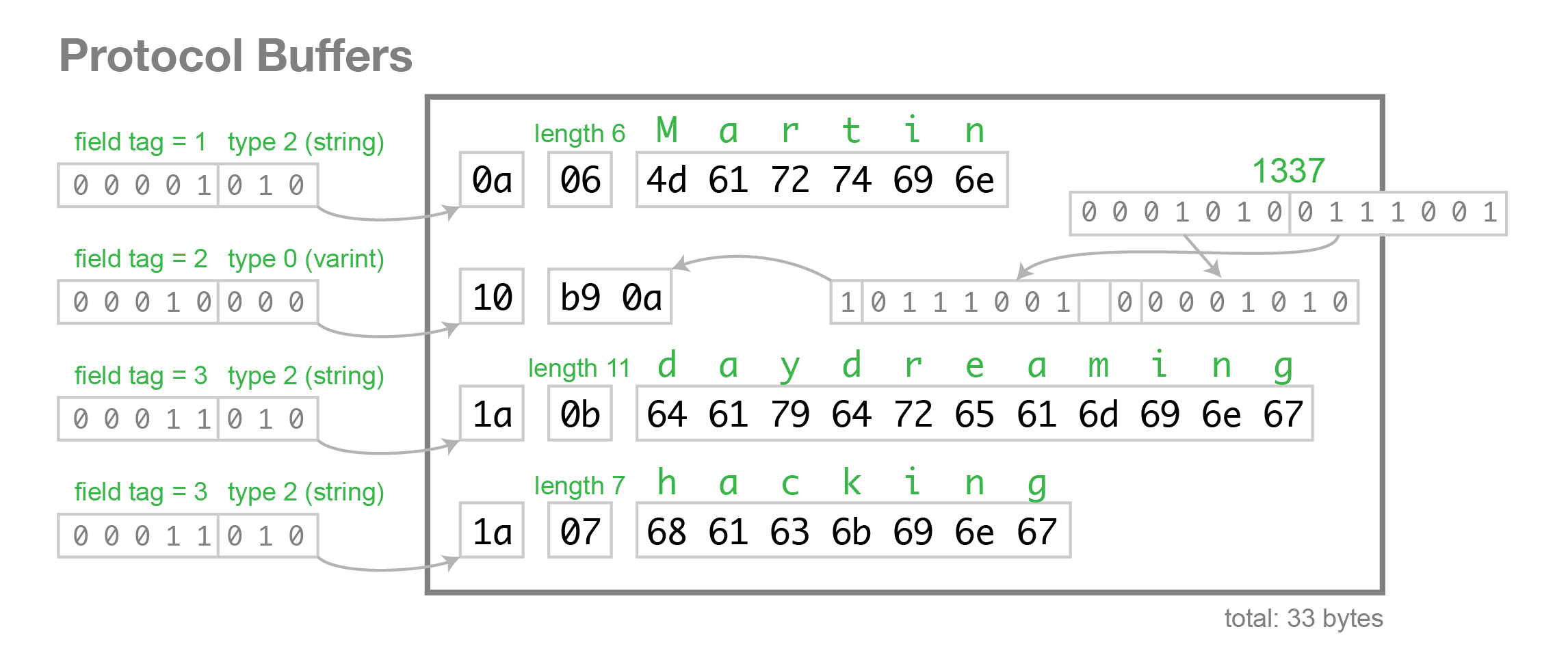
Look exactly at how the binary representation is structured, byte by byte. The person record is just
the concatentation of its fields. Each field starts with a byte that indicates its tag number (the
numbers 1, 2, 3 in the schema above), and the type of the field. If the first byte of a field
indicates that the field is a string, it is followed by the number of bytes in the string, and then
the UTF-8 encoding of the string. If the first byte indicates that the field is an integer, a
variable-length encoding of the number follows. There is no array type, but a tag number can appear
multiple times to represent a multi-valued field.
This encoding has consequences for schema evolution:
optional, required and repeated fields
(except for the number of times the tag number can appear). This means that you can change a field
from optional to repeated and vice versa (if the parser is expecting an optional field but
sees the same tag number multiple times in one record, it discards all but the last value).
required has an additional validation check, so if you change it, you risk runtime errors (if
the sender of a message thinks that it’s optional, but the recipient thinks that it’s required).optional field without a value, or a repeated field with zero values, does not appear in
the encoded data at all — the field with that tag number is simply absent. Thus, it is safe to
remove that kind of field from the schema. However, you must never reuse the tag number for
another field in future, because you may still have data stored that uses that tag for the field
you deleted.This approach of using a tag number to represent each field is simple and effective. But as we’ll see in a minute, it’s not the only way of doing things.
Avro schemas can be written in two ways, either in a JSON format:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favouriteNumber", "type": ["null", "long"]},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}…or in an IDL:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Notice that there are no tag numbers in the schema! So how does it work?
Here is the same example data encoded in just 32 bytes:
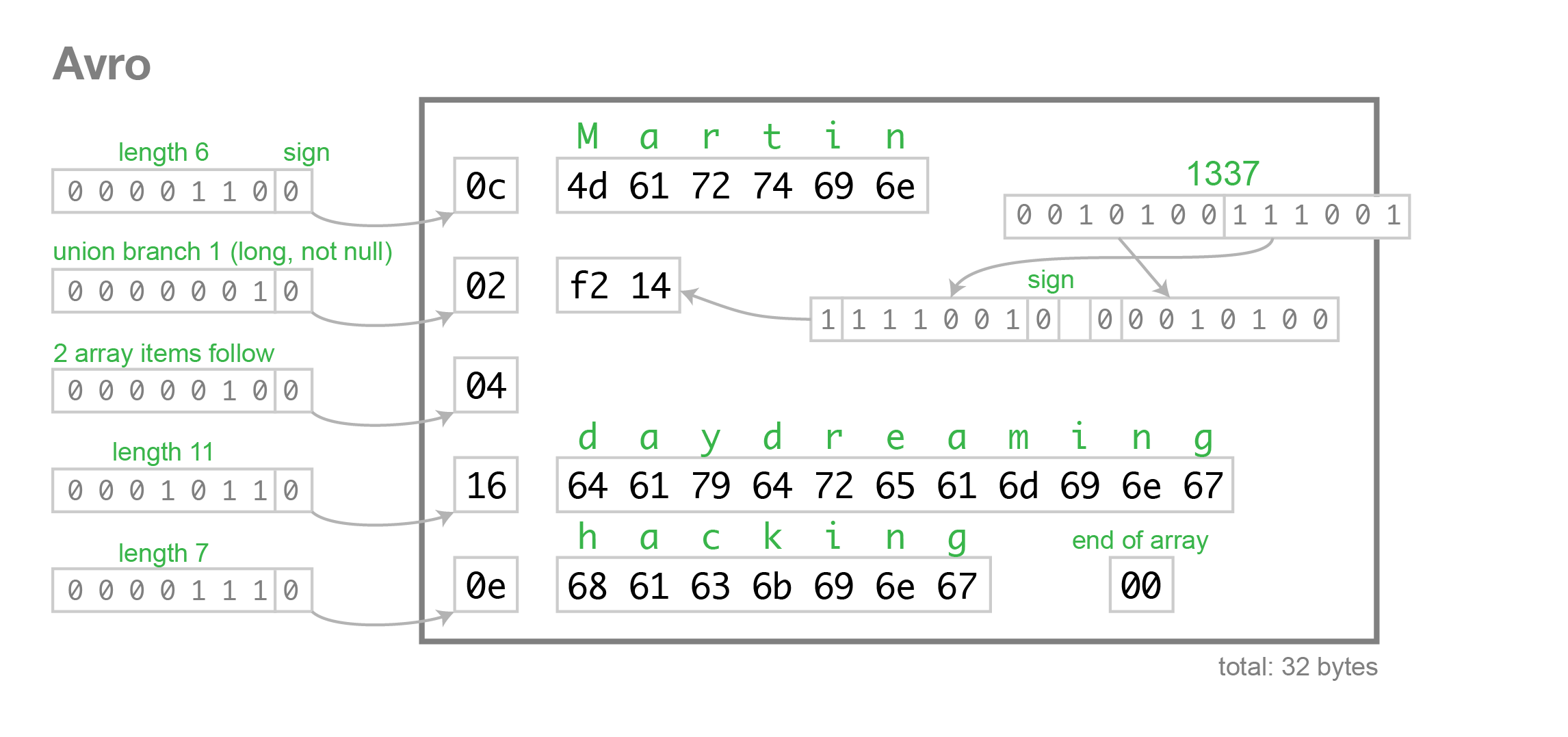
Strings are just a length prefix followed by UTF-8 bytes, but there’s nothing in the bytestream that tells you that it is a string. It could just as well be a variable-length integer, or something else entirely. The only way you can parse this binary data is by reading it alongside the schema, and the schema tells you what type to expect next. You need to have the exact same version of the schema as the writer of the data used. If you have the wrong schema, the parser will not be able to make head or tail of the binary data.
So how does Avro support schema evolution? Well, although you need to know the exact schema with which the data was written (the writer’s schema), that doesn’t have to be the same as the schema the consumer is expecting (the reader’s schema). You can actually give two different schemas to the Avro parser, and it uses resolution rules to translate data from the writer schema into the reader schema.
This has some interesting consequences for schema evolution:
union { null, long }
above. This is encoded as a byte to tell the parser which of the possible union types to use,
followed by the value itself. By making a union with the null type (which is simply encoded as
zero bytes) you can make a field optional.null if
the field’s type is a union with null). The default is necessary so that when a reader using the
new schema parses a record written with the old schema (and hence lacking the field), it can fill
in the default instead.This leaves us with the problem of knowing the exact schema with which a given record was written. The best solution depends on the context in which your data is being used:
One way of looking at it: in Protocol Buffers, every field in a record is tagged, whereas in Avro, the entire record, file or network connection is tagged with a schema version.
At first glance it may seem that Avro’s approach suffers from greater complexity, because you need to go to the additional effort of distributing schemas. However, I am beginning to think that Avro’s approach also has some distinct advantages:
Thrift is a much bigger project than Avro or Protocol Buffers, as it’s not just a data serialization library, but also an entire RPC framework. It also has a somewhat different culture: whereas Avro and Protobuf standardize a single binary encoding, Thrift embraces a whole variety of different serialization formats (which it calls “protocols”).
Indeed, Thrift has two different JSON encodings, and no fewer than three different binary encodings. (However, one of the binary encodings, DenseProtocol, is only supported in the C++ implementation; since we’re interested in cross-language serialization, I will focus on the other two.)
All the encodings share the same schema definition, in Thrift IDL:
struct Person {
1: string userName,
2: optional i64 favouriteNumber,
3: list<string> interests
}
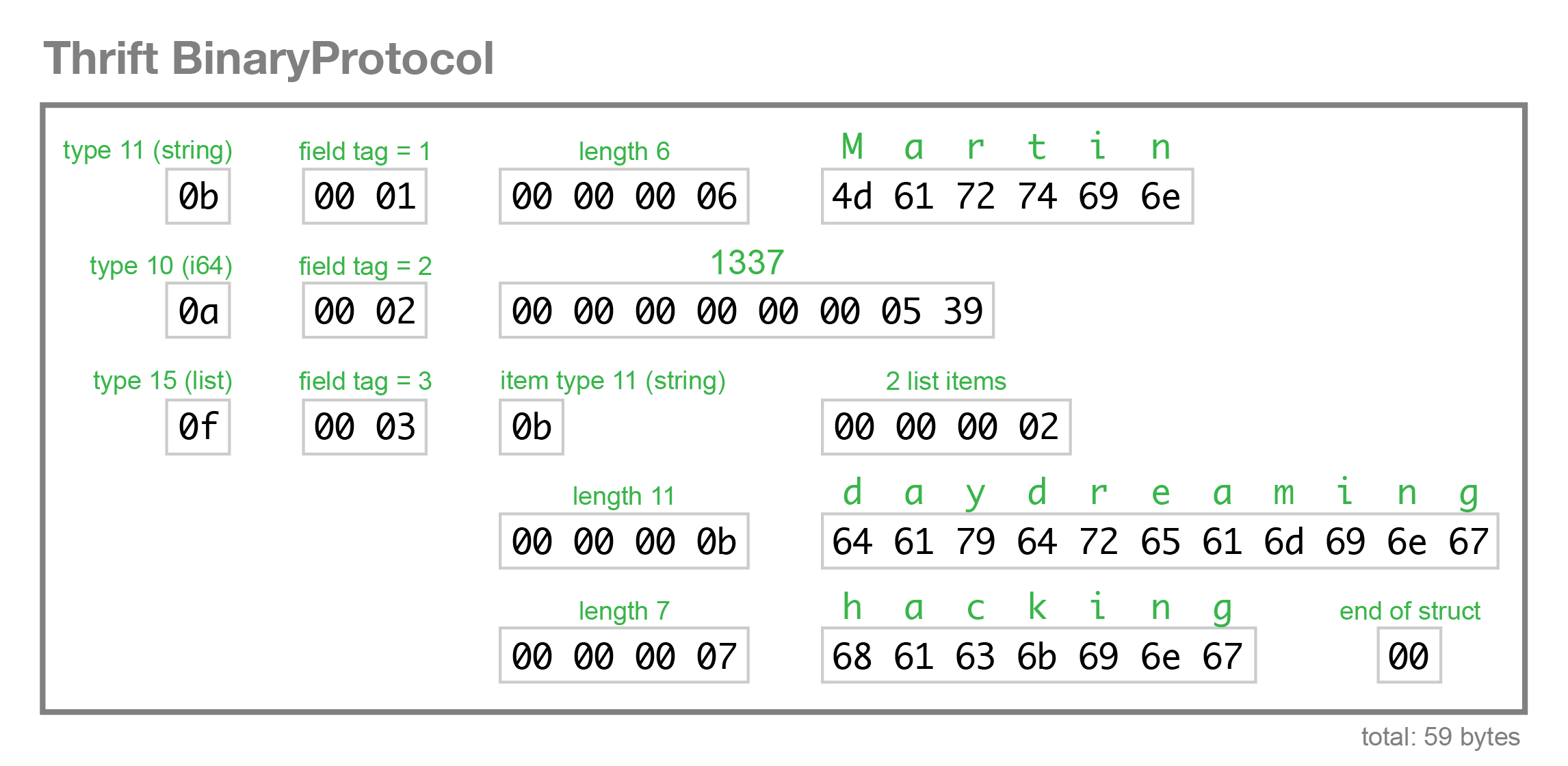
The BinaryProtocol encoding is very straightforward, but also fairly wasteful (it takes 59 bytes to encode our example record):
The CompactProtocol encoding is semantically equivalent, but uses variable-length integers and bit packing to reduce the size to 34 bytes:
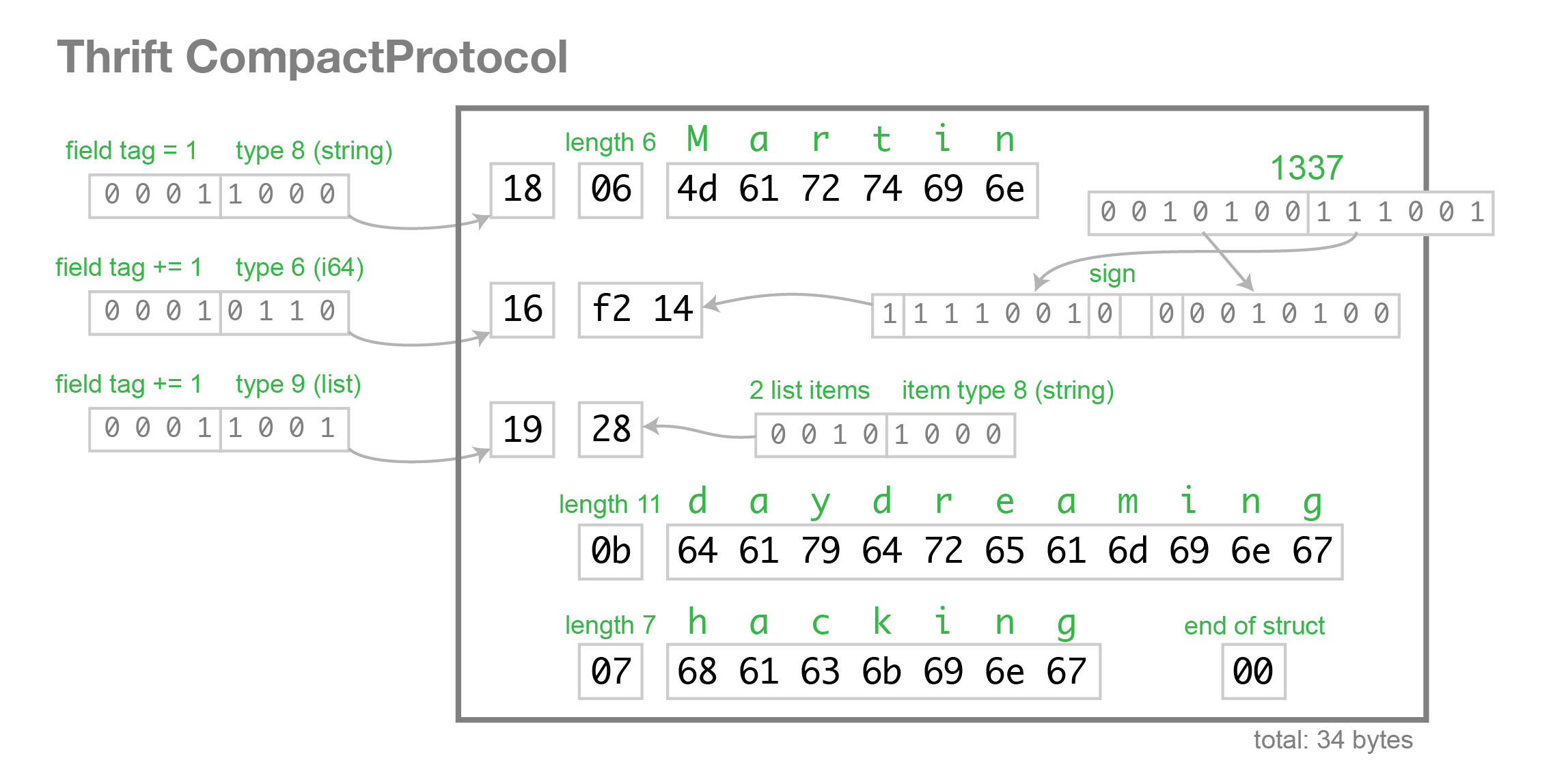
As you can see, Thrift’s approach to schema evolution is the same as Protobuf’s: each field is manually assigned a tag in the IDL, and the tags and field types are stored in the binary encoding, which enables the parser to skip unknown fields. Thrift defines an explicit list type rather than Protobuf’s repeated field approach, but otherwise the two are very similar.
In terms of philosophy, the libraries are very different though. Thrift favours the “one-stop shop” style that gives you an entire integrated RPC framework and many choices (with varying cross-language support), whereas Protocol Buffers and Avro appear to follow much more of a “do one thing and do it well” style.
This post has been translated into Korean by Justin Song, and into Chinese by 李君.
If you found this post useful, please support me on Patreon so that I can write more like it!
To get notified when I write something new, follow me on Bluesky or Mastodon, or enter your email address:
I won't give your address to anyone else, won't send you any spam, and you can unsubscribe at any time.
My book, Designing Data-Intensive Applications, has received thousands of five-star reviews.
![]() Unless otherwise specified, all content on this site is licensed under a
Creative Commons
Attribution 3.0 Unported License.
Theme borrowed from
Carrington,
ported to Jekyll by Martin Kleppmann.
Unless otherwise specified, all content on this site is licensed under a
Creative Commons
Attribution 3.0 Unported License.
Theme borrowed from
Carrington,
ported to Jekyll by Martin Kleppmann.