My book

My book, Designing Data-Intensive Applications, has received thousands of five-star reviews.
Published by Martin Kleppmann on 12 Oct 2022.
This post also appears on Larry Paulson’s blog.
We use distributed systems every day in the form of internet services. These systems are very useful, but also challenging to implement because networks are unpredictable. Whenever you send a message over the network, it is likely to arrive quite quickly, but it’s possible that it might be delayed for a long time, or never arrive, or arrive several times.
When you send a request to another process and don’t receive a response, you have no idea what happened: was the request lost, or has the other process crashed, or was the response lost? Or maybe nothing was lost at all, but a message has simply been delayed and may yet arrive. There is no way of knowing what happened, because unreliable message-passing is the only way how processes can communicate.
Distributed algorithms work with this model of unreliable communication and build stronger guarantees on top of it. Examples of such stronger guarantees include database transactions and replication (maintaining copies of some data on multiple machines so that the data is not lost if one machine fails).
Unfortunately, distributed algorithms are notoriously difficult to reason about, because they must uphold their guarantees regardless of the order in which messages are delivered, and even when some messages are lost or some processes crash. Many algorithms are very subtle, and informal reasoning is not sufficient for ensuring that they are correct. Moreover, the number of possible permutations and interleavings of concurrent activities quickly becomes too great for model-checkers to test exhaustively. For this reason, formal proofs of correctness are valuable for distributed algorithms.
In this blog post we will explore how to use the Isabelle/HOL proof assistant to formally verify a number of distributed algorithms. Isabelle/HOL does not have any built-in support for distributed computing, but fortunately it is quite straightforward to model a distributed system using structures that Isabelle/HOL provides: functions, lists, and sets.
First, we asssume each process (or node) in the system has a unique identifier, which could simply be an integer or a string. Depending on the algorithm, the set of process IDs in the system may be fixed and known, or unknown and unbounded (the latter is appropriate for systems where processes can join and leave over time).
The execution of the algorithm then proceeds in discrete time steps. In each time step, an event occurs at one of the processes, and this event could be one of three things: receiving a message sent by another process, receiving user input, or the elapsing of a timeout.
datatype ('proc, 'msg, 'val) event
= Receive (msg_sender: 'proc) (recv_msg: 'msg)
| Request 'val
| TimeoutTriggered by one of these events, the process executes a function that may update its own state, and may send messages to other processes. A message sent in one time step may be received at any future time step, or may never be received at all.
Each process has a local state that is not shared with any other process. This state has a fixed initial value at the beginning of the execution, and is updated only when that process executes a step. One process cannot read the state of another process, but we can describe the state of the entire system as the collection of all the processes’ individual states:
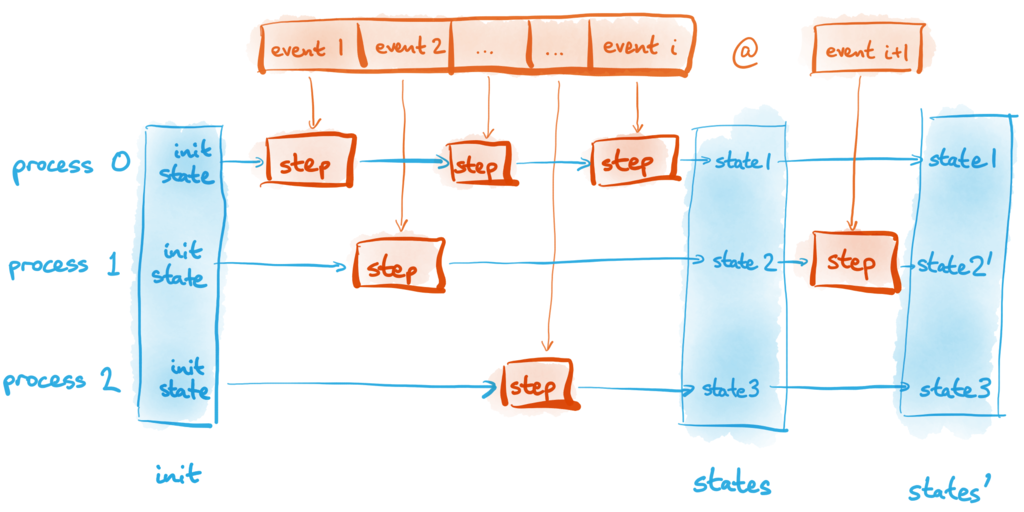
Even though in reality processes may run in parallel, we do not need to model this parallelism since the only communication between processes is by sending and receiving messages, and we can assume that a process finishes processing one event before starting to process the next event. Every parallel execution is therefore equivalent to some linear sequence of execution steps. Other formalisations of distributed systems, such as the TLA+ language, also use such a linear sequence of steps.
We do not make any assumptions about which time step is executed by which process. It is possible that the processes fairly take turns to run, but it is equally possible for one process to execute a million steps while another process does nothing at all. By avoiding assumptions about process activity we ensure that the algorithm works correctly regardless of the timing in the system. For example, a process that is temporarily disconnected from the network is modelled simply by a process that does not experience any receive-message events, even while the other processes continue sending and receiving messages.
In this model, a process crash is represented simply by a process that executes no more steps after some point in time; there is no need for a crash to be explicitly represented. If we want to allow processes to recover from a crash, we can add a fourth type of event that models a process restarting after a crash. When executing such a crash-recovery event, a process deletes any parts of its local state that are stored in volatile memory, but preserves those parts of its state that are in stable storage (on disk) and hence survive the crash.
When reasoning about safety properties of algorithms, it is best not to assume anything about which process executes in which time step, since that ensures the algorithm can tolerate arbitrary message delays. If we wanted to reason about liveness (for example, that an algorithm eventually terminates), we would have to make some fairness assumptions, e.g. that every non-crashed process eventually executes a step. However, in our proofs so far we have only focussed on safety properties.
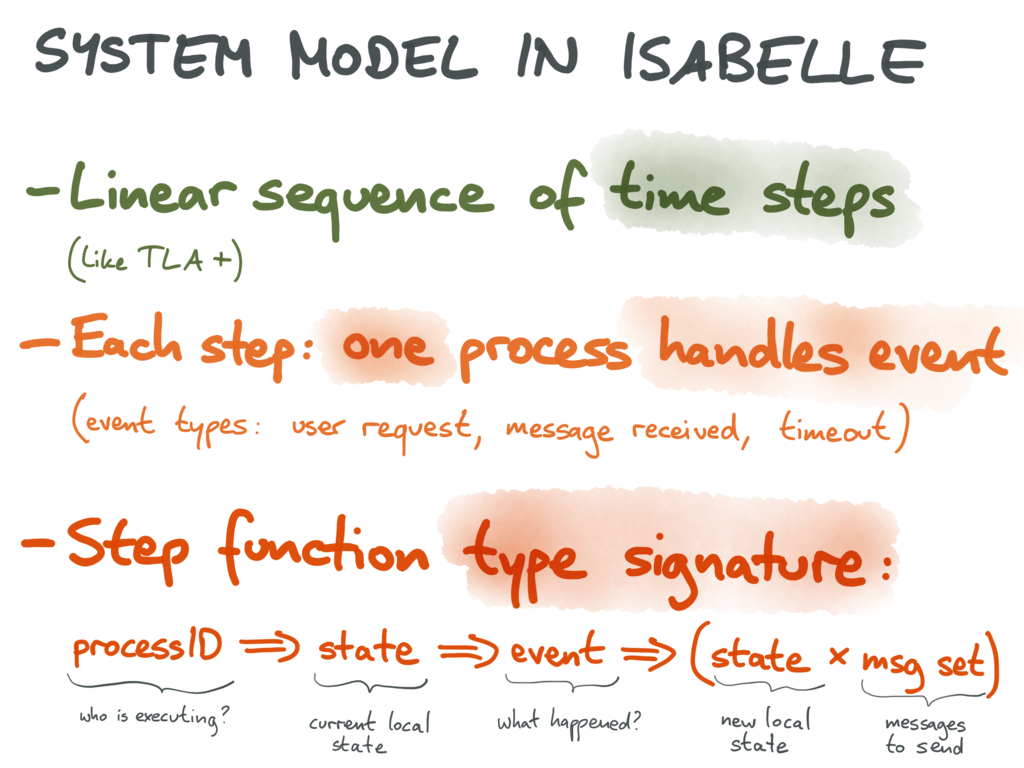
We can now express a distributed algorithm as the step function, which takes three arguments: the ID of the process executing the current time step, the current local state of that process, and the event that has occurred (message receipt, user input, timeout, or crash recovery). The return value consists of the new state for that process, and a set of messages to send to other processes (each message tagged with the ID of the recipient process).
type_synonym ('proc, 'state, 'msg, 'val) step_func =
‹'proc ⇒ 'state ⇒ ('proc, 'msg, 'val) event ⇒
('state × ('proc × 'msg) set)›The current state of a process at one time step equals the new state after the previous step by the same process (or the initial state if there is no previous step). Assuming the step function is deterministic, we can now encode any execution of the system as a list of (processID, event) pairs indicating the series of events that occurred, and at which process they happened. The final state of the system is obtained by calling the step function one event at a time.
To prove a distributed algorithm correct, we need to show that it produces a correct result in every possible execution, i.e. for every possible list of (processID, event) pairs. But which executions are possible? There is only really one thing we can safely assume: if a message is received by a process, then that message must have been sent to that process. In other words, we assume the network does not fabricate messages out of thin air, and one process cannot impersonate another process. (In a public network where an attacker can inject fake packets, we would have to cryptographically authenticate the messages to ensure this property, but let’s leave that out of scope for now.)
Therefore, the only assumption we will make is that if a message is received in some time step, then it must have been sent in a previous time step. However, we will allow messages to be lost, reordered, or received multiple times. Let’s encode this assumption in Isabelle/HOL.
First, we define a function that tells us whether a single event is possible: (valid_event evt proc msgs) returns true if event evt is allowed to occur at process proc in a system in which msgs is the set of all messages that have been sent so far. msgs is a set of (sender, recipient, message) triples. We define that a Receive event is allowed to occur iff the received message is in msgs, and Request or Timeout events are allowed to happen anytime.
fun valid_event :: ‹('proc, 'msg, 'val) event ⇒ 'proc ⇒
('proc × 'proc × 'msg) set ⇒ bool›
where
‹valid_event (Receive sender msg) recpt msgs =
((sender, recpt, msg) ∈ msgs)› |
‹valid_event (Request _) _ _ = True› |
‹valid_event Timeout _ _ = True›Next, we define the set of all possible event sequences. For this we use an inductive predicate in Isabelle: (execute step init procs events msgs states) returns true if events is a valid sequence of events in an execution of the algorithm where step is the step function, init is the initial state of each process, and proc is the set of all processes in the system (which might be infinite if we want to allow any number of processes). The last two arguments keep track of the execution state: msgs is the set of all messages sent so far, and states is a map from process ID to the state of that process.
inductive execute ::
‹('proc, 'state, 'msg, 'val) step_func ⇒ ('proc ⇒ 'state) ⇒
'proc set ⇒ ('proc × ('proc, 'msg, 'val) event) list ⇒
('proc × 'proc × 'msg) set ⇒ ('proc ⇒ 'state) ⇒ bool›
where
‹execute step init procs [] {} init› |
‹⟦execute step init procs events msgs states;
proc ∈ procs;
valid_event event proc msgs;
step proc (states proc) event = (new_state, sent);
events' = events @ [(proc, event)];
msgs' = msgs ∪ {m. ∃(recpt, msg) ∈ sent.
m = (proc, recpt, msg)};
states' = states (proc := new_state)
⟧ ⟹ execute step init procs events' msgs' states'›This definition states that the empty list of events is valid when the system is in the initial state and no messages have been sent. Moreover, if events is a valid sequence of events so far, and event is allowed in the current state, then we can invoke the step function, add any messages it sends to msgs, update the state of the appropriate process, and the result is another valid sequence of events.
And that’s all we need to model the distributed system!
Now we can take some algorithm (defined by its step function and initial state) and prove that for all possible lists of events, some property P holds. Since we do not fix a maximum number of time steps, there is an infinite number of possible lists of events. But that’s not a problem, since we can use induction over lists to prove P.
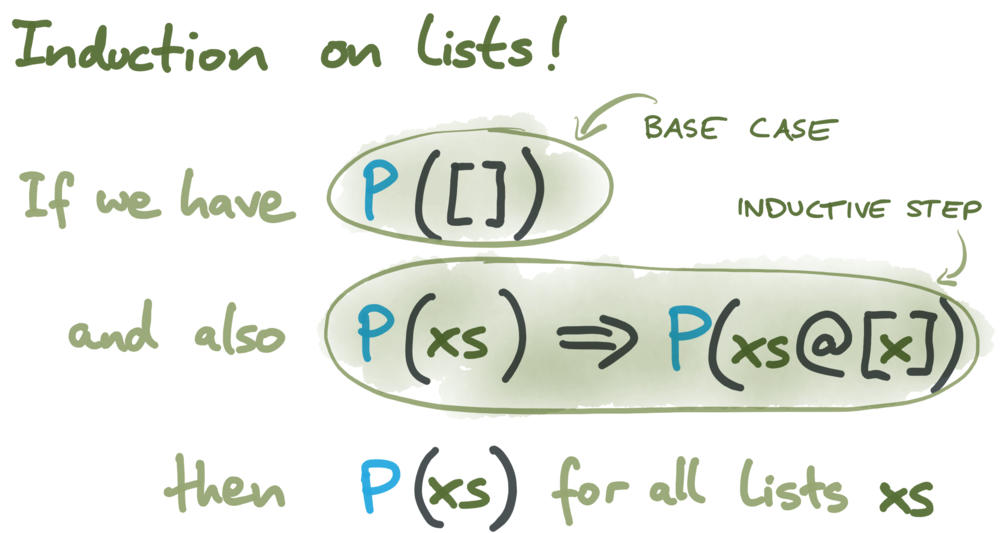
We use the List.rev_induct induction rule in Isabelle/HOL. It requires showing that:
In other words, we prove that P is an invariant over all possible states of the whole system. In Isabelle, that proof looks roughly like this (where step, init, and procs are appropriately defined):
theorem prove_invariant:
assumes ‹execute step init procs events msgs states›
shows ‹some_invariant states›
using assms proof (induction events arbitrary: msgs states
rule: List.rev_induct)
case Nil
then show ‹some_invariant states› sorry
next
case (snoc event events)
then show ?case sorry
qedThe real challenge in verifying distributed algorithms is to come up with the right invariant that is both true and also implies the properties you want your algorithm to have. Unfortunately, designing this invariant has to be done manually. However, once you have a candidate invariant, Isabelle is very helpful for checking whether it is correct and whether it is strong enough to meet your goals.
For more detail on how to prove the correctness of a simple consensus algorithm in this model, I recorded a 2-hour video lecture that runs through a demo from first principles (no prior Isabelle experience required). The Isabelle code of the demo is also available.
If you want to work on this kind of thing, I will soon be looking for a PhD student to work with me on formalising distributed algorithms in Isabelle, based at TU Munich. If this sounds like something you want to do, please get in touch!
If you found this post useful, please support me on Patreon so that I can write more like it!
To get notified when I write something new, follow me on Bluesky or Mastodon, or enter your email address:
I won't give your address to anyone else, won't send you any spam, and you can unsubscribe at any time.
My book, Designing Data-Intensive Applications, has received thousands of five-star reviews.
![]() Unless otherwise specified, all content on this site is licensed under a
Creative Commons
Attribution 3.0 Unported License.
Theme borrowed from
Carrington,
ported to Jekyll by Martin Kleppmann.
Unless otherwise specified, all content on this site is licensed under a
Creative Commons
Attribution 3.0 Unported License.
Theme borrowed from
Carrington,
ported to Jekyll by Martin Kleppmann.